建模师们有福了!蜂窝配资
不用在建模、UV、贴图软件之间反复横跳,一个工作台就能得到:

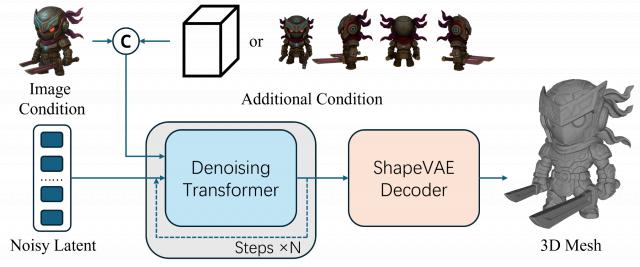
这是腾讯专为3D设计师、游戏开发者、建模师等打造的专业级AI工作台混元3D Studio。
一个平台搞定整套设计流程,不管是前期的概念设计、几何建模,还是进一步的组件拆分、低模拓扑,以及后续贴图、绑骨蒙皮、动画等都能全覆盖。
这下真让3D资产生产周期从几天变成分分钟了。
那它是怎么做到的呢?让我们来个深度剖析。
核心架构
混元3D Studio整体是一个顺序且模块化的工作流程。
其中每个阶段都会对资产进行处理,并为下一个阶段提供至关重要的数据输入。从最初的创意到最终的游戏资产,这一设计确保了整个过程的无缝衔接与自动化。

混元3D Studio工作流
整个工作流共包含:
组件拆分:利用连通性分析和语义分割算法,复杂模型能够被自动拆解为逻辑上和功能上独立的组件(例如:步枪的弹匣、枪管和枪托),从而实现组件的独立编辑和动画制作。
可控图像生成(概念设计):文本或图像皆可作为输入模态,支持文生图和图生多视图功能。此外,专用的A-Pose标准化模块确保角色模型骨架姿势的一致性,风格迁移模块则用于调整图像视觉效果,以匹配目标游戏的美术风格。
高保真几何生成:基于当前先进的扩散模型架构,根据单视图或多视图图像生成精细的三维网格模型(高模)。得益于强大的跟随能力,能够确保生成的几何结构与输入prompt高度一致,并极大地还原物体的3D表面细节。
低模拓扑生成(PolyGen):该模块摒弃传统的基于图形学的重拓扑方法,采用自回归模型逐面地生成低多边形资产。通过将几何表面的点云作为条件输入,PolyGen能够智能生成高保真网格对应的拓扑结构,适用于游戏资产等应用场景,满足低顶点数、结构合理以及良好变形适应的边流分布。
语义UV展开:不同于传统的语义性差的传统UV展开方法与人工UV展开。语义UV展开模块实现了具备上下文语义感知的UV切线生成,可以依据模型的形状与布线分布进行结构分析,提升UV拆分的语义性、合理性与可用性,进而有利于高质量纹理的生成。
纹理生成与编辑:集成了生成式大模型,可根据文本或图像prompt生成物理准确的PBR纹理,并通过无损编辑层,支持用户使用自然语言指令对纹理进行精细化二次调整。
绑骨蒙皮&动画特效:在自动化的最后阶段,该模块能够推断骨骼关节位置与层级结构,并计算顶点权重,生成可直接用于标准游戏引擎的可驱动动画资产。
共七个核心技术模块,其中每个模块都对应资产制作流程中的某一关键阶段,下面一个个来看。
组件拆分
团队提出了一种用于打造可投入生产、可编辑且结构合理的三维资产的新范式。
给定一张输入图片,首先使用Huyuan3D获取整体形状。然后,将整体网格传递给部件检测模块P3-SAM,以获得语义特征和部件的边界框(bounding boxes)。最后,由X-Part将整体形状分解为各个部件。

组件拆分整体流程
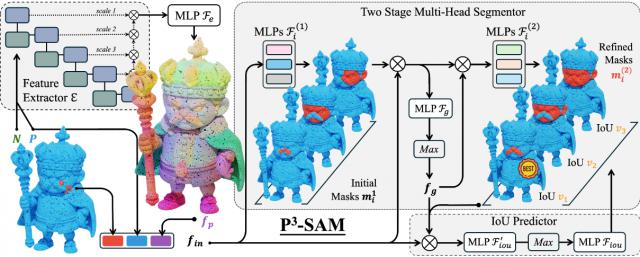
其中,P3-SAM(原生3D语义分割)是组件拆分生成流程中的关键步骤。
P3-SAM包含一个特征提取器、三个分割头和一个IoU(交并比)预测头。
混元3D Studio工作流
PointTransformerV3作为特征提取器,并融合其不同层级的特征作为点级特征。
输入的点提示和特征信息会被融合,并传递至分割头,用于预测三个多尺度掩码。
同时,IoU预测头用于评估掩码质量。为实现物体的自动分割,利用FPS(最远点采样)生成点提示,配合NMS(非极大值抑制)合并冗余掩码。
点级掩码随后被投影到网格面上,从而获得部件分割结果。
本方法的另一关键创新在于,完全摒弃2D SAM的影响,依赖于原生3D部件监督,进行原生3D分割模型的训练。
还提出了一个可控且可编辑的扩散框架X-Part。
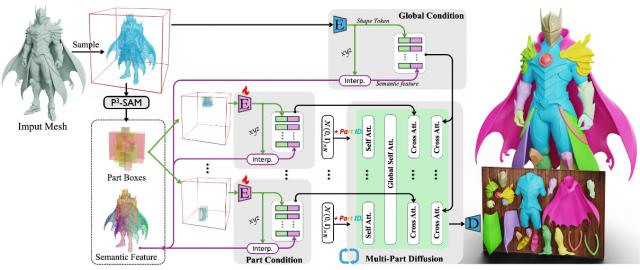
X-Part流程
首先,为实现可控性提出了一个基于部件级提示的特征提取模块,利用包围盒作为提示,指示部件的位置和尺寸,而不是直接将分割结果作为输入。
其次,将语义特征以精心设计的特征扰动方式引入到框架中,这有助于实现有意义的部件分解。
为了验证X-Part的有效性,在多个基准数据集上进行了大量实验。结果表明,X-Part在组件级分解和生成方面取得了当前最优的表现。
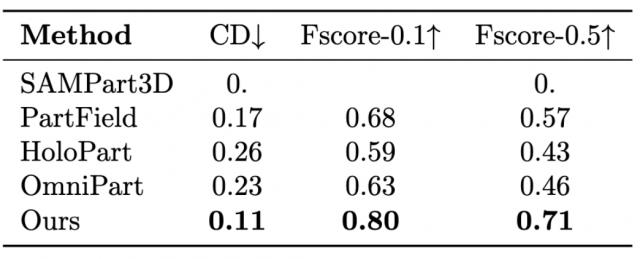
横向量化比较
组建拆分横向效果对比
可控图像生成包含图像风格化与姿态标准化两大模块。
图像风格化模块允许用户在3D建模前蜂窝配资,通过配置选项一键生成多种主流游戏美术风格的3D设计图。
用户可提供任务对象图像,并通过文本的风格化指令。格式为"Change the style to {style type} 3D model. White Background.",从而生成内容保持一致且艺术风格精准符合指令要求的风格化输出。
训练数据以三元组形式构建: {输入参考图像,风格类型,风格化3D设计图},实现对写实图像与风格化作品的精确映射。
针对无参考图像的文本到图像风格化的应用场景,系统先用自研通用文本图像生成模型合成参考图像,再经过图像风格化流水线,最终输出风格化作品。

风格化效果展示
针对任意角色参考图像的姿态标准化(如A-pose),需兼顾姿态精准控制和角色一致性的严格保持,并需实现对参考图像中背景和道具的消除。
为此,团队将含任意姿态/视角的角色图像作为条件输入,注入来引导生成过程。
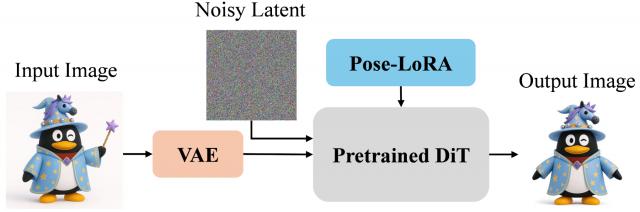
姿态标准化流程图
数据集构建:首先基于角色渲染数据,构建[任意姿态/视角角色图像,标准A-pose正面图像]的图像对。
随后,将含有道具(如手持武器、基座等)的渲染数据输入编辑模型,剥离角色本体之外的道具与背景,保证形象一致性。最终所得图像对经人工筛选,纳入数据集,使模型具备道具与背景剔除能力。
训练策略采用了分辨率递进思路,自512×512起步,逐步升至768×768,促使模型更好地学习细粒度特征,显著提升生成图像在面部、复杂服饰等细节部分的保真度。
此外,针对同一角色在不同场景下的参考图像进行随机条件输入,提升姿态泛化能力和生成一致性。
团队还特别收集了高质量数据集,涵盖半身像、非人型类人物及拟人化角色等难度类型,并在后期采用SFT和DPO进一步微调,增强模型泛化性与鲁棒性。

姿态标准化效果高保真几何生成
高保真几何生成的工作流水线基于业界领先的Hunyuan3D框架,整体结构包含如下两个子模块:
Hunyuan3D-ShapeVAE:一种变分编码–解码式的Transformer结构,先对三维几何体进行压缩,再进行重构。
该模块的编码器输入带有三维位置和表面法向的点云,经过基于Vector-Set Transformer的重要性采样,嵌入为紧凑的形状潜变量z。解码器则利用z查询基于均匀网格的三维神经场,位置网格为,最终将神经场Fg映射为符号距离函数(SDF)值。
几何生成流程
Hunyuan3D-DiT:一种基于流的扩散模型,直接在ShapeVAE的潜空间操作。
网络由21层Transformer堆叠而成,每层包含Mixture-of-Experts (MoE)子层,有效提升模型容量与表达力。
Hunyuan3D-DiT通过流匹配目标训练,将高斯噪声映射到形状潜变量,实现形状生成的高效及高质量采样。
Hunyuan3D-DiT主要以单张输入图像为条件进行生成。该图像首先被调整至518×518尺寸,背景被移除,随后通过冻结的DINOv2骨干网络[7]编码为图像潜变量,并通过交叉注意力融合到生成的形状潜变量中。
为了进一步提供几何和先验指导,Hunyuan3D-Studio引入了两项补充控制信号:
包围盒条件控制。对于给定的包围盒,将其高、宽、长编码为,具体方式为两层 MLP。随后,将与图像潜变量按序列维度拼接,形成最终条件向量。
在训练过程中,有意对图像或点云进行微小的形变,使得图像中的物体比例与对应点云不完全一致,从而促使模型学会响应包围盒这一控制信号。
多视图图像生成条件。为充分利用图像生成模型的强大能力,将多视角图像(由扩散模型生成)作为角色建模的额外条件约束。
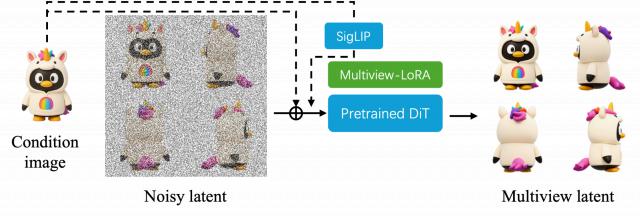
多视图生成流程
单图到多视图图像生成。如图所示,为了从单张输入图像高保真地合成多视角视图,本方案在预训练文本到图像基础模型之上引入轻量LoRA适配层。训练数据集由任意视角摄像机采集的物体中心视图及其对应的多视图真实图像对组成。
训练时,通过模型原生的变分自编码器(VAE)分别将单视图输入与多视图目标编码为潜在表达。
LoRA层以两个信息源为条件:一是无噪单视图图像的潜变量(与加噪的多视图潜变量拼接用于结构引导);二是借助预训练 SigLIP 视觉编码器提取的输入图像语义条件向量。最终用标准流匹配损失优化LoRA参数。
多视图条件注入。与单图条件类似,首先将所有视角图像编码为图像潜变量。每个除原始图像外的视图都注入一个带固定索引的正弦位置编码。其后,所有生成视图的潜变量与原始图像潜变量在序列维度拼接,形成最终条件向量。
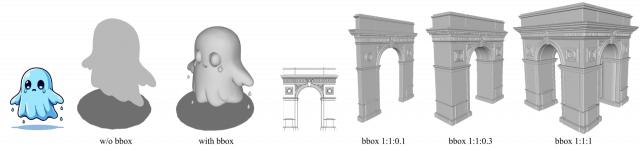
包围盒条件控制生成效果

多视图条件控制生成效果展示低模拓扑
在几何生成高模或用户提供的模型基础上,低模拓扑模块的目标是生成干净、符合美术规范的拓扑结构。
尽管在高保真几何生成模块或组件拆分模块已经生成了精致的形状,这些形状通常由大量杂乱的三角面组成,难以直接用于下游应用(如语义UV展开和绑定)。
因此,采用自回归模型,直接从生成形状的点云预测低模拓扑的顶点和面。

低模拓扑整体结构图
网格分词化(Mesh Tokenization)。为了以下一个token预测范式建模网格蜂窝配资,第一步是将其分词为一维序列。
采用了Blocked and Patchified Tokenization (BPT)作为网格的基础分词方法。具体来说,BPT结合了两个核心机制:
1)块级索引(Block-wise Indexing),它将三维坐标划分为离散空间块,将笛卡尔坐标转化为块偏移索引,以利用空间的局部性;
2)Patch聚合(Patch Aggregation),通过选取高度数顶点作为patch中心,将相连面片聚合为统一的patch,进一步压缩面片级数据。每个patch以中心顶点及其外围顶点的顺序进行编码,减少了顶点的重复,提高了空间一致性。通过BPT,模型的训练和推理效率都得到了显著提升。
网络结构。低模拓扑模块的网络结构由点云编码器和自回归网格解码器组成。点云编码器主要受到Michelangelo和 Hunyuan3D系列的启发,采用Perceiver架构,将点云编码为条件编码cp。
随后,采用Hourglass Transformer作为网格解码器骨干,通过交叉注意力层以点云token作为条件进行解码。
训练和推理策略。网格token的分布由带参数的Hourglass Transformer建模,通过最大化对数概率进行训练。不同的条件cp通过交叉注意力(cross-attention)融合进模型。
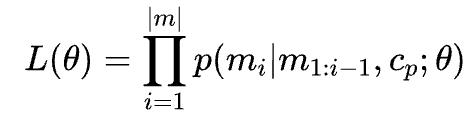
为了进一步利用高多边形网格数据并提升训练效率,本方案采用了截断训练策略(truncated training strategy)。具体来说,每次训练迭代时,会随机选取长度为固定面数(如4k面)的网格序列片段进行训练。而在推理阶段,我们应用滚动缓存(rolling cache)策略,以缩小训练和推理阶段之间的差异。
基于拓扑感知掩码的DPO网格生成后训练。本方案建立了一条用于第二阶段微调的偏好数据集构建流程,该流程包含候选生成、多指标评估和偏好排序。对于每个输入点云P ,我们利用预训练模型生成八个候选网格。
每个候选网格会通过三项指标进行评估:边界边比(Boundary Edge Ratio, BER)和拓扑分数(Topology Score, TS)用于衡量拓扑质量,豪斯多夫距离(Hausdorff Distance, HD)用于衡量几何一致性。
当且仅当满足以下条件时,偏好关系被定义:
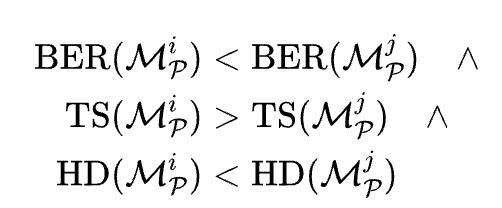
从所有两两比较中整理出偏好三元组,以构建数据集。
为了解决局部几何缺陷和面密度不一致的问题,采用了掩码直达偏好优化(Masked Direct Preference Optimization, M-DPO),它在DPO的基础上扩展了质量感知的定位掩码。本节定义了一个二值掩码函数,该函数用于根据每个面的质量评估将高质量区域(值为1)与低质量区域(值为0)区分开来。
每个区域对应于块补丁分词(block patch tokenization, BPT)中的一个子序列。只有当子序列中的所有面片的四边形比例超过预设阈值且平均拓扑分数超出另一阈值时,该子序列才会被判定为高质量区域。令为冻结的参考模型,为可训练策略。M-DPO的目标函数为:
其中,正项和负项分别是:
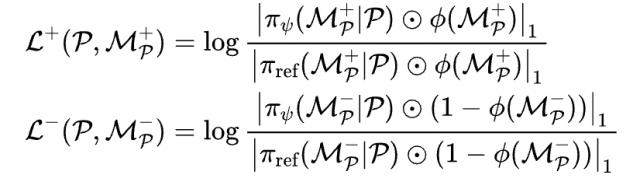
这里,表示元素逐位相乘,是范数。M-DPO实现了对低质量区域的有针对性的细化,同时保持了质量令人满意的区域。
下图展示了后训练后的改进效果,实验结果表明后训练阶段对于提升生成网格的完整性和拓扑质量至关重要。
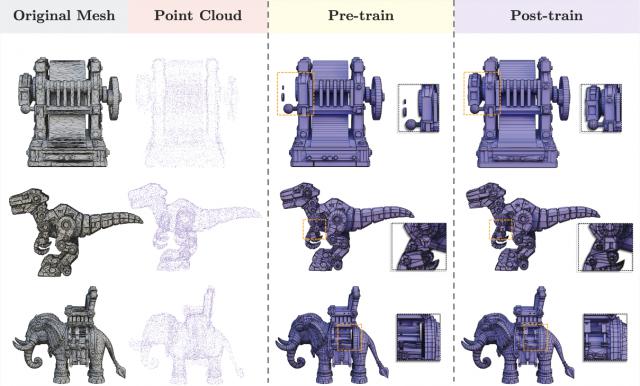
预训练预后训练效果对比
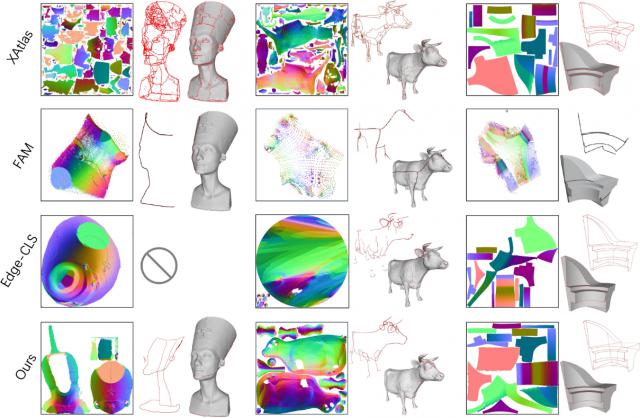
如图所示,本方案与现有的低模拓扑方法对比如下。从图中可以看出,本方案能够生成结构更复杂且拓扑质量和稳定性显著提升的网格。

与其他方案效果对比

基于组件拆分Mesh的低模拓扑生成效果

不同面数级别低模拓扑效果对比语义UV展开
传统UV展开方法的结果往往缺乏语义意义,这将显著影响后续贴图的质量与资源利用效率。
因此,这些传统方法难以直接应用于游戏开发、影视制作等专业流水线。为应对这一挑战,本节提出了一个通过自回归方式生成艺术家风格裁切缝的新型框架SeamGPT。
将曲面裁切问题建模为序列预测任务,将裁切缝表示为有序的三维线段序列。给定输入网格M,目标是生成缝边。SeamGPT的整体流程如下图所示。
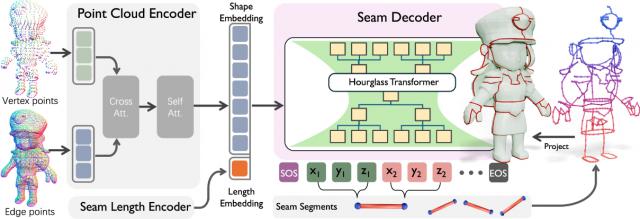
SeamGPT整体架构图
本方案采用两种损失函数进行模型训练:用于token预测的交叉熵损失和用于正则化形状嵌入空间的KL散度损失,确保该空间保持紧凑且连续。模型经过一周训练后收敛。
训练期间,首先将所有样本缩放至一个立方体边界框内,范围为−1到1。随后应用数据增强技术,包括在 [0.95,1.05]区间内的随机缩放、随机顶点抖动和随机旋转。
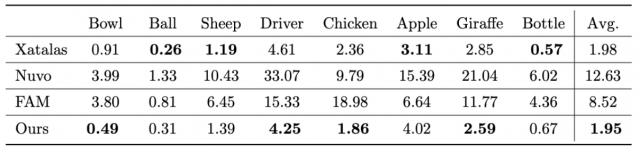
与其它方法的量化比较
可视化对比纹理生成与编辑
混元3D团队提出了一种高保真的纹理合成方法:将二维扩散模型扩展为几何条件下的多视角生成模型,并通过视图投影将其结果烘焙为高分辨率的纹理贴图。
该体系结构系统性地解决了多视角纹理生成的两个核心挑战:
跨视角一致性与几何对齐;
RGB纹理向光照真实PBR材质纹理的扩展
本节将纹理生成框架扩展为支持多模态纹理编辑的综合系统。
首先,增强了现有的多视角基于物理渲染(PBR)材质生成模型,以支持文本和图像引导的多模态编辑。
其次,提出了一种基于材质的三维分割方法,能够从仅含几何信息的输入网格中生成按部件划分的材质分割图,实现局部纹理编辑。
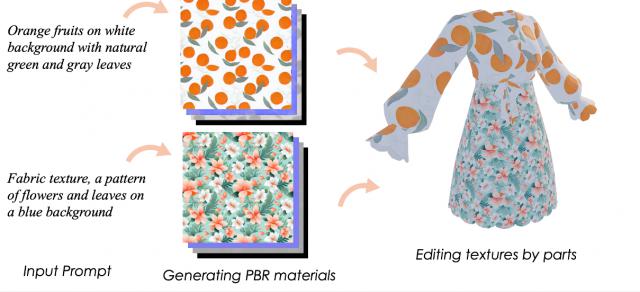
最后,引入了一种4K材质球生成模型,能够根据文本提示合成高分辨率的可平铺纹理球,包括基础色(Base Color)、金属度(Metallic)、粗糙度(Roughness)和法线贴图(Normal),以支持专业的艺术创作流程。
多模态纹理编辑。本节引入了一种文本引导的纹理编辑模型,该模型基于精心整理的包含8万份高质量PBR材质三维资产的数据集进行训练。
这些资产被渲染成多视角的HDR图像,并借助视觉-语言模型(Vision-Language Model, VLM)生成了纹理描述性标题和编辑指令。
利用图像编辑模型框架,构建了覆盖多视角的大规模图像编辑对。
随后,纹理基础模型从这些图像对中推断出一致的多视角纹理,合成了大量文本-纹理配对,用于微调编辑模型。在训练过程中,将文本提示和参考图像特征统一编码为联合潜变量序列。
基于基础纹理生成模型,系统通过3万对文本-纹理样本实现端到端优化,最终得到一个能够在文本和视觉指导下进行纹理合成与编辑的统一模型。
针对图像引导的纹理编辑模型,提出了一种简化的专家混合(Mixture of Experts,MoE)架构,以处理多样化的图像输入。
为判断输入图像是否与目标几何体匹配,团队计算几何渲染视图与输入图像之间的CLIP相似度。当引导图像与目标网格具有较高的几何对应关系时,通过变分自编码器(VAE)编码器注入图像特征;
否则,采用CLIP图像嵌入进行特征融合,类似于IP-Adapter的方法。这种自适应条件机制确保在任意图像条件下实现鲁棒的纹理编辑。

文本和图像引导的纹理编辑
上图展示了令人惊叹的多模态编辑效果,表明能够对游戏中的物体(如道具和角色)进行多样风格的材质编辑,且支持全局和局部修改。
基于材质的3D分割。对于分割任务,本方案采用了类似于PartField的分割框架。
该框架首先从输入的点云或网格数据中提取特征,随后基于提取的三维点特征进行聚类,将三平面(triplane)表示转换为更紧凑的VecSet表示。
特征提取模块通过包含30万个三维资产的数据集进行端到端训练。
在零件标注方面,利用了原始三维资产中嵌入的材质槽和零件标注,同时过滤掉不可靠的零件数据。
在聚类过程中,采用SAM来确定初始的聚类中心数量,从而保证聚类的鲁棒性和性能。
材质图生成流程
4K材质图生成。本节创新性地改编了原本用于编码连续视频帧的3D VAE框架,将多域材质数据(包括渲染图、基础色、凹凸、粗糙度、金属度等)压缩为统一的潜在表示,从而实现可扩展的4K分辨率纹理合成。
具体而言,通过带有纹理的三维资产对3D VAE进行微调,以实现域不变的特征提取,得到一个PBR-VAE模块。随后,使用材质球数据集对3D扩散变压器(Diffusion Transformer,DiT)进行微调,构建了材质球生成模型的核心架构。
绑骨蒙皮&动画特效
本节介绍了绑骨蒙皮与动画特效模块,该模块由两大部分组成:人形角色动画模块和通用角色动画模块。
每个角色输入首先经过检测模块处理。如果输入被判定为人形角色,则进入人形动画分支;否则,转入通用动画分支。
人形分支包括基于模板的自动绑定模块和动作重定向模块。
为在骨骼生成的准确性与易用性之间取得平衡,团队采用22个身体关节作为模板骨骼。类似构建绑定与蒙皮模型,但与其在蒙皮预测中未融合绑定相关信息不同,本方案的模型同时整合骨骼特征和顶点特征,以实现更精确的结果。
此外,系统还包含姿势标准化模块,将用户提供的任意姿势模型转换为标准的T型姿势。将T型姿势模型输入动作重定向模块,可获得更可靠且精确的效果。
相较之下,通用分支融合了自回归骨骼生成模块与几何拓扑感知蒙皮模块。由于通用角色在骨骼拓扑和关节数量上存在差异,大多数现有骨骼生成方法基于自回归技术,本研究模块即建立在这些自回归方法之上。
关于蒙皮模块,以往算法通常仅将网格顶点和骨骼关节作为输入特征,较少关注它们之间的拓扑关系。相比之下,团队的蒙皮模块显式融合了这些拓扑关系,从而带来更稳健和稳定的结果。
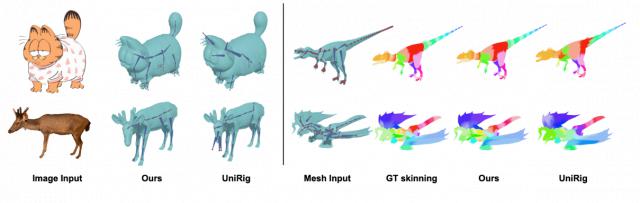
与其它方法的绑骨蒙皮效果对比

动作驱动效果展示
以上模块通过统一的资产图进行协同管理,各阶段输出的元数据会传递至下游流程。
这种机制实现了参数化控制,使高层次的美术调整能够贯穿整个管线,同时具备可逆性,支持增量式更新而无需全量重算。
最终输出可以根据目标游戏引擎(如Unity或Unreal Engine)的规范进行配置与导出。
感兴趣的朋友可戳下方链接体验~
体验地址:https://3d.hunyuan.tencent.com/studio
技术报告:https://arxiv.org/pdf/2509.12815
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🏆 年度科技风向标「2025人工智能年度榜单」评选报名开启啦!我们正在寻找AI+时代领航者 点击了解详情
❤️🔥 企业、产品、人物3大维度,共设立了5类奖项,欢迎企业报名参与 👇
一键关注 👇 点亮星标
科技前沿进展每日见蜂窝配资
贵丰配资提示:文章来自网络,不代表本站观点。
相关文章



沪深京指数
热点资讯




